Your boss has just handed you a legacy c application and wants you to start writing tests for it. Testing is important. So you start writing, but you come across an all too common problem – in one set of tests, you want to test higher level functionality so you need a sub for the actual functionality, and in another set of tests you want to test lower level functions so you need the actual implementation. As is frequently the case, test problems come from dependencies. One solution is to use completely separate test projects for each test (that could potentially be a lot of projects!). Or James Grenning has proposed a different solution to this problem, use function pointers. Here is what James says about it:
“Create a function pointer with the same signature as the problem function. By default initialize the pointer with the problem function. Change clients to call through the function pointer. Override the function in the tests where needed.”
This is just one example of using them in legacy code. Since a function pointer is simply a pointer that points to a function (executable code) instead of data, legacy code uses them a lot for instance for call back routines. Which will allow you to call a function that you specify at runtime. Function pointers can also be used if your design calls for swappable device drivers or swappable implementations. With swappable device drivers, you may not know if certain functionality is supported by your target platform until runtime. They are also used in task schedules to dynamically call which functions are executed in a task table or in complex state machines. As you can see, function pointers can be very useful. For a thorough introduction to using them in embedded software, I would suggest Jacob Beningo’s article “Function Pointers: An Introduction”.
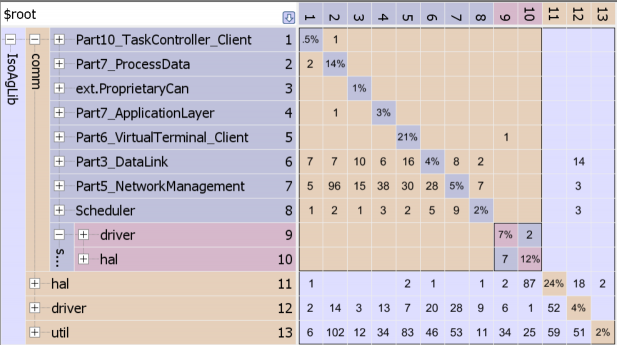
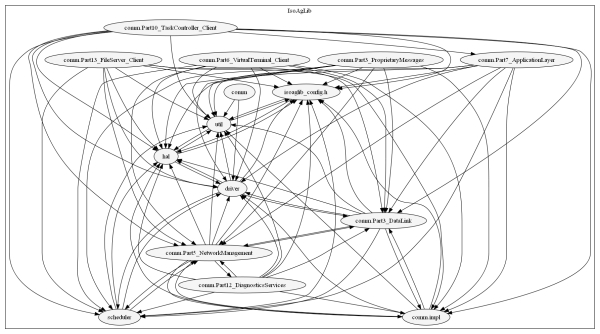
The problem is that while function pointers provide a more dynamic way to call code it is at the expense of readability and understanding. Many people shy away from using them and some companies have completely banned their use, because of the increased complexity. But there are benefits to function pointers. As in the example above they can improve testability by allowing you to use test subs at times and real functionality other times. This is a good design practice as a good design is testable. Part of the problem is that there is limited support for function pointers from tool vendors. As an example, defining function pointers is out of scope of the UML specification so most UML vendors don’t support function pointers. But this is changing, SciTools Understand has recently added support for function pointers, because of this Lattix now also offers support for function pointers through its Understand module. This is significant because the scalability of the Dependency Structure Matrix (or Design Structure Matrix) with the added support of function pointers, the number of dependencies (or potential dependencies) can be quite large making a traditional call graph hard to read, as seen below:
as you can see the Dependency Structure Matrix can handle this easily:
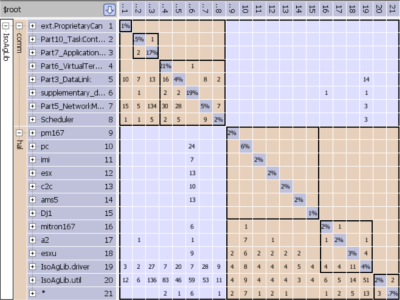
The Dependency Structure Matrix helps improve readability and understanding by:
- Applying partitioning and clustering algorithms to discover the layers and independent components.
- Even if the architecture is eroded, this process identifies dependencies that lead to the discovery of unintended layers.
- Experimenting with what-if architectures by creating logical models to examine dependencies
- Example: if you are looking to componentize, then create logical components using the current set of files/classes/elements. If there are no dependencies between these components and they are intended to be independent of each other, then the componentization works. On the other hand, if there are dependencies between these components, you know what dependencies to eliminate.
- Making the code understandable and maintainable with a clear understanding of the architecture that will prevent further erosion.
- Making rules that prevent changes from causing erosion
manage the evolution of system design, supporting technologies such as C/C++, Java, .NET, Fortran, Ada, Javascript, Actionscript, Pascal, Python, UML/SysML, Rhapsody, Sparx EA,
Oracle, SQLServer, Sybase, LDI and Excel.
If you would like to try out the new function pointer functionality in Lattix, sign up for a demonstration and free trial.